Don’t Build a Distributed Monolith
An architecture that combines all the network latency, failure modes, and operational complexity of a distributed system with the tight coupling and deployment bottlenecks of a monolith. It is the worst of both worlds.
It is one of the most common failure modes in modern system design. Teams, intending to build resilient and scalable microservices, accidentally create a far more brittle and complex system...
This note captures the core definitions and common mistakes that lead to this anti-pattern, providing clear concepts to help articulate and avoid these architectural pitfalls.
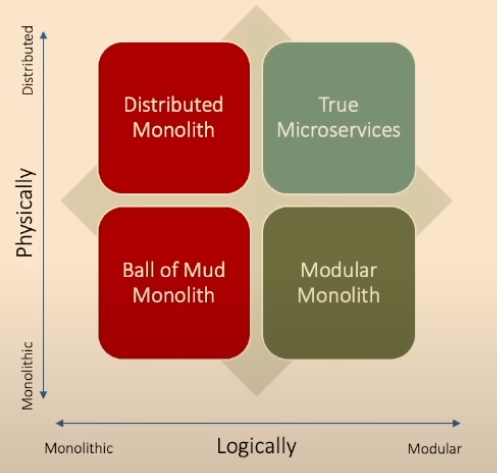
The Four Architectures: Good vs. Bad
The quality of an architecture depends on two axes: how it's logically structured (coupling) and how it's physically deployed.
- Ball of Mud Monolith (Bad): Physically monolithic, logically monolithic. The classic spaghetti-code monolith where everything is tightly coupled. Changes in one area create bugs in another.
- Modular Monolith (Good): Physically monolithic, logically modular. A single, deployable application with well-defined internal boundaries. This is often the best starting point for most systems.
- True Microservices (Good, if you need it): Physically distributed, logically modular. Independent services that can be developed, deployed, and scaled separately. This is the ideal, but it comes at a high cost.
- Distributed Monolith (The Monster 👹): Physically distributed, logically monolithic. The architecture we must avoid. It looks like microservices on the surface, but a change in one service requires changes and redeployments across many others.
The Great Trade-Off: Consistency vs. Availability
The fundamental reason to choose a microservice architecture is to make a trade-off. You are sacrificing Immediate Consistency to gain High Availability.

- Monoliths are excellent at immediate consistency. A single database transaction ensures all data is consistent at once. However, a full-app deployment is required for any change, and a failure in one component can bring down the entire system, reducing availability.
- Microservices excel at high availability. A single service can fail or be taken down for maintenance without affecting the others. However, achieving consistency across multiple services and databases is incredibly complex, requiring asynchronous patterns and eventual consistency.
If your team or business problem does not require this specific trade-off, you likely do not need microservices.
How did we end up with a distributed monolith?
1. The Shared Database
This is the most common and destructive mistake. Multiple "microservices" all read from and write to the same database.
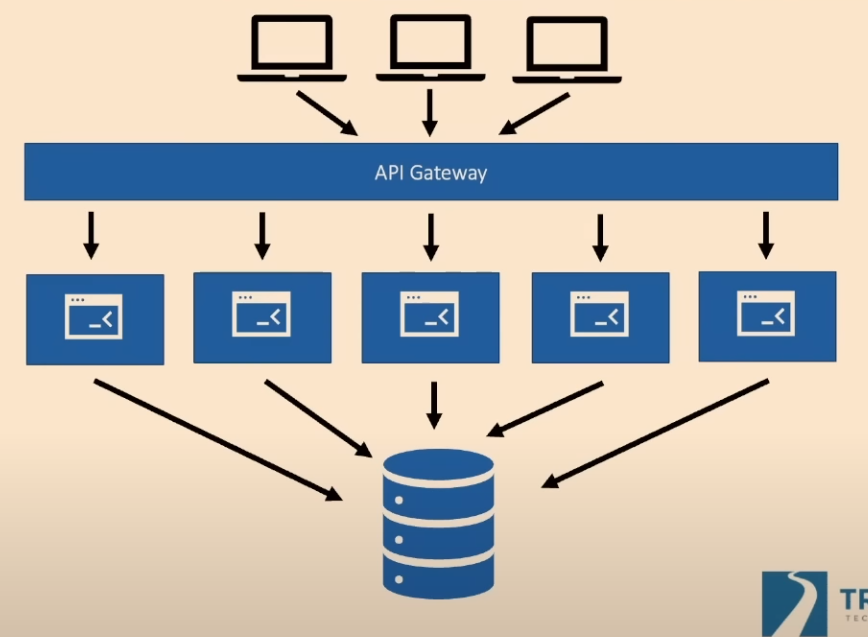
- Why it's a disaster: It creates extreme data coupling. A schema change required by one service can break all other services. It completely negates the core benefit of microservices: independent deployability. Each service does not truly own its data or its fate.
2. Chatty, Synchronous Communication
Services that make frequent, blocking (synchronous) calls to each other are a classic sign of incorrect boundaries.
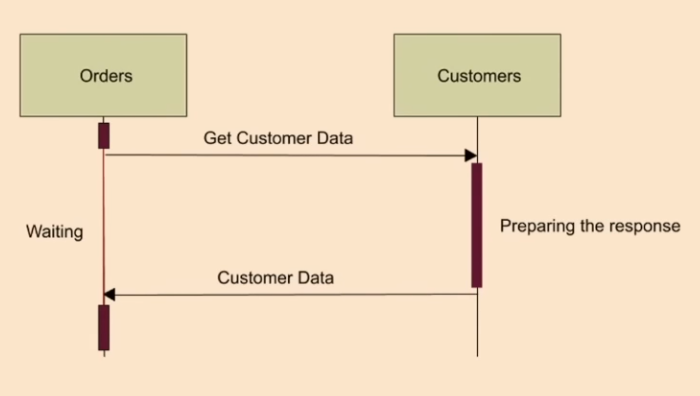
- Why it's a disaster: It creates temporal coupling. If the
Customersservice is slow or down, theOrdersservice is now also slow or down. This leads to cascading failures, where a problem in one service ripples through the entire system, destroying the high-availability promise of the architecture.
3. Starting with a Greenfield Microservices Project
It is far harder to get service boundaries right when starting from scratch ("greenfield") than when migrating an existing system ("brownfield").
- Why it's harder: In a greenfield project, you are guessing at the domains and boundaries. With a brownfield monolith, you have invaluable artifacts:
- Existing Code: The code itself is documentation of the current relationships and domains.
- People: You can talk to the teams who know the system and its pain points.
- A Working System: You have a system that already works and can be migrated piece by piece, reducing risk.
What About Our Event-Driven Services on Kubernetes?
As an organization that relies heavily on stream processors (pulling from Pub/Sub, processing, and publishing new events), you might think we're safe from the classic distributed monolith. We don't have chatty synchronous calls, right?
The danger is still very real. The anti-pattern just takes a different form. The tight coupling simply shifts from synchronous API calls to the data schemas, processing chains, and shared infrastructure that connect our services.
Here are the common pitfalls for our kind of architecture:
1. Coupling Through a Shared Event Schema
This is the event-driven equivalent of the Shared Database. One service publishes an event, and five other services consume it. The event's data structure (its schema) becomes a rigid, shared contract.
-
The Disaster: The producing service needs to add a field or change a data type. If they deploy this change, they might instantly break all five consuming services, causing data loss or processing failures across the system. Now, a simple change to one service requires a coordinated, multi-team deployment effort. This is the deployment lock-in of a monolith, just hidden behind a Pub/Sub topic.
-
How to mitigate:
- Promote Schema Registries: Advocate for tools like a central Avro or Protobuf schema registry. This allows schemas to be versioned and managed explicitly.
- Tolerant Consumers: Encourage teams to build services that can ignore unknown fields. This makes the system more resilient to non-breaking schema changes from upstream producers.

2. Coupling Through Long, Brittle Processing Chains
We often see a business process implemented as a long, sequential chain of services: Service A -> Service B -> Service C -> Service D. Each service pulls from the previous one's output topic, adds a little value, and publishes to the next topic.
-
The Disaster: This isn't a set of independent microservices; it's a distributed Rube Goldberg machine. The services have no independent value. If
Service Bgoes down or has a bug, the entire chain from that point forward halts. The blast radius of a single failure is enormous, and debugging the end-to-end flow becomes a nightmare. -
How to mitigate:
- Question the Chain: When a new service is proposed, ask: "What happens if the service before you is down for an hour? What happens if the service after you is down?" This probes for temporal coupling.
- Advocate for Idempotency and DLQs: Ensure services can safely re-process messages from a Dead-Letter Queue (DLQ). This is our primary tool for recovering from a failure in the middle of a chain.
3. Coupling Through The "God Topic"
This is the temptation to create a single, central Pub/Sub topic, like all-company-events, where every service publishes everything.
-
The Disaster: This topic becomes a single point of failure and a massive bottleneck.
- Performance: Dozens of services are all trying to read from the same topic, creating "noisy neighbor" problems.
- Reliability: A single "poison pill" message (a malformed event) can be consumed by every service, potentially causing a widespread outage.
- Change Management: Any change to any event on that topic requires notifying every team that consumes from it. Innovation grinds to a halt.
-
How to mitigate:
- Promote Domain-Specific Topics: Push for topics that are scoped to a specific business domain (e.g.,
orders.v1,customer-updates.v1). This naturally isolates concerns. - Isolate Infrastructure: Ensure services have their own service accounts and IAM permissions. Don't let every service in the cluster have permission to read/write to every topic. This limits the blast radius of a compromised or misbehaving service.
- Promote Domain-Specific Topics: Push for topics that are scoped to a specific business domain (e.g.,
Actionable advice
- First Rule of Microservices: Don't Use Microservices. (Sam Newman). Challenge the "why." Unless a team can clearly articulate the trade-offs they need (e.g., independent deployability for organizational scaling, or extreme precision scaling for a specific service), a microservice architecture is likely a premature optimization that will introduce immense operational complexity.
- Advocate for the Modular Monolith or Macroservices. For most teams, the best architecture is a single deployable unit with clean, logical boundaries. This provides the development speed of a monolith while preparing you to "strangle" out a true microservice later if—and only if—the need arises. The Macroservices pattern is the modern, domain-aware evolution of this idea.
- Promote Asynchronous Communication. Encourage the use of an Event Bus (e.g., Kafka, RabbitMQ, cloud-native queues) for inter-service communication. This decouples services in time and is the primary defense against the cascading failures caused by synchronous calls.
- Insist on Bounded Contexts. The goal of a microservice is to be the smallest possible unit that can operate without chatty communication. If two services are constantly calling each other or sharing data, they are not separate domains. They belong together in the same service. This is the core principle of Domain-Driven Design (DDD).
Resources
- Talk on YouTube: Don't Build a Distributed Monolith - Jonathan "J." Tower
- Speaker: Jonathan "J." Tower
- Domain-Driven Design - Eric Evans